Journey of Zone Aware Traffic
Today, I want to share a bit of details in our steps to support zone aware traffic in our Kubernetes infrastructure.
You can learn a bit of Kubernetes and see interesting effects it can have. First I have to share something about the environment.
Starting from zero!
There are basically two patterns in Kubernetes infrastructure deployments:
- 1 Kubernetes cluster per zone
- 1 Kubernetes cluster per region with multiple zones.
In our case it’s the latter, a single Kubernetes cluster spans multiple zones, 3 by default. The advantage is that you have more simple availability guarantees, because all your applications run across 3 zones by default. On the other hand, doing traffic engineering, so prefer close instances, is more complex. Before I tell about the problem space and our findings, let me share our basic Kubernetes Ingress setup. It is a 2-layer load balancer infrastructure serving a large scale microservice environment.
In German there is a proverb that says one picture is better than thousands of words, so let’s see figure 1. It’s a bit outdated, because we run AWS network load balancer (NLB) instead of ALB, but rest looks the same today.

figure 1
We terminate TLS in the cloud load balancer and the HTTP routing is done in our HTTP proxy skipper. Cloud load balancers are managed by kube-ingress-aws-controller and DNS by external-dns.
We run this for about a decade since Kubernetes 1.3 and it evolved quite a bit. If you want to lurk into our configuration, check it out in kubernetes-on-aws.
In this environment zone aware traffic has 4 parts:
- client to cloud load balancer
- cloud load balancer to skipper-ingress (skipper-ingress is the application based on skipper that is the data-plane and control-plane of our http proxy layer)
- skipper-ingress to backend pods
- cluster internal clients to skipper-ingress through a service type ClusterIP
Kube-ingress-aws-controller manages ALBs and NLBs, so 1. and 2. are
done, that one. You can set -nlb-cross-zone=false to disable sending
traffic cross zone from the load balancer TargetGroup to
skipper-ingress. If you set
--nlb-zone-affinity=availability_zone_affinity all clients running
in the same zone in any AWS account will resolve DNS to same zone. So
instead of 3 IPs for NLB Listeners you will resolve only one. It does
not matter if you have a client in the same or in another cluster.
Since
v0.24.22
skipper supports zone aware traffic (3.) in its kubernetes
dataclient. Dataclients are the way to fetch data, that skipper uses
to create its routing table. If you run skipper-ingress with the
kubernetes dataclient configured, every skipper-ingress pod will fetch
all relevant Kubernetes objects to build its routing tree. In larger
environments this is quite some load on the Kubernetes control plane
and it’s easy to break Kubernetes control plane by scaling out. The
skipper way to control the load targeting the Kubernetes control plane
is to run skipper’s routesrv.
Routesrv
is a skipper control plane component. It uses the Kubernetes dataclient to fetch
routing information and exposes an API endpoint to fetch eskip
routes. Eskip
is the skipper native routing language. Eskip has a set of paradigms:
- Routes match by
predicates - Predicates can be combined by
&&(logical AND), if you need a logical OR, you have to create another route. - Features in the request or response path are implemented in
filters. - Backends are more than a list of load balancer pool members.
Eskip examples:
// syntax
routeID: Predicate1 && Predicate2 -> filter1 -> filter2 -> <backend>;
r1: Path("/resource/:id") -> setRequestHeader("X-Resource-Id", "${id}") -> clusterClientRatelimit("resource", 10, "1m", "X-Resource-Id") -> "https://backend.example.org";
r2: Host("products.example.org") && Path("/products/:productId")
-> consistentHashKey("${productId}")
-> consistentHashBalanceFactor(1.25)
-> <consistentHash, "http://127.0.0.1:9998", "http://127.0.0.1:9997">;
Coming back to zone aware traffic.
If your data-plane skipper-ingress fetches routes from a control plane component like routesrv, the question is:
How does routesrv know where the skipper-ingress pod is running, that queries it?
Astonishing: routesrv has no idea!
Routesrv just exposes route API endpoints, that are used by the data-plane pods to fetch routes:
/routesfetch all routes/routes/:zonefetch zone aware routes
Skipper-ingress data plane pods know its zone by Kubernetes downwards API. This makes it possible to pass Kubernetes metadata to the process by environment variables:
1env:
2- name: KUBE_NODE_ZONE
3 valueFrom:
4 fieldRef:
5 fieldPath: metadata.labels['topology.kubernetes.io/zone']
Now you can use the environment variable in a flag to skipper like
-routes-urls=http://skipper-ingress-routesrv.kube-system.svc.cluster.local/routes/$(KUBE_NODE_ZONE)" to fetch zone aware routes.
Great, now we understand how we can do zone aware traffic 1.-3., but what about 4.?
Ok, 4. seems to be easy. You just plug an annotation
service.kubernetes.io/topology-mode: auto and kube-proxy will make
sure your ClusterIP service is having a safe amount of Kubernetes pods
in its layer 4 load balancer. We run this since more than 3 years
without an issue. Before this annotation there was
service.kubernetes.io/topology-aware-hints annotation which did
basically the same thing. If you read the
documentation,
you see that there are some thoughts about safety, because you do not
want to create harm on a data-plane feature that every application has
to rely on.
As often in a life, things change. Sometimes implementation changes or your monitoring adds more visibility. Your application requirements on the infrastructure change or traffic patterns, because someone deployed a new client to some service. Sometimes it’s a mixture of all of this visible in figure 2.
To understand better the zonal traffic in our clusters we created a graph how much requests by zone we have in skipper-ingress data-plane. If we have some new data and it shows something unexpected, my first question is always: can we trust the data? Sometimes we do mistakes, like having a wrong unit or some selector is slightly wrong and you observe not exactly what you expected. So a bit of questioning your new data is always a great thing to find bugs.
However, in this case it seems we really were able to trust the data. During the last weeks we had some interesting effects in one of our high traffic clusters. The effects are shown in figure 2. We can see that within 1h there were 3 times a large share of throughput that hit only one zone. After some minutes it was going back to normal.
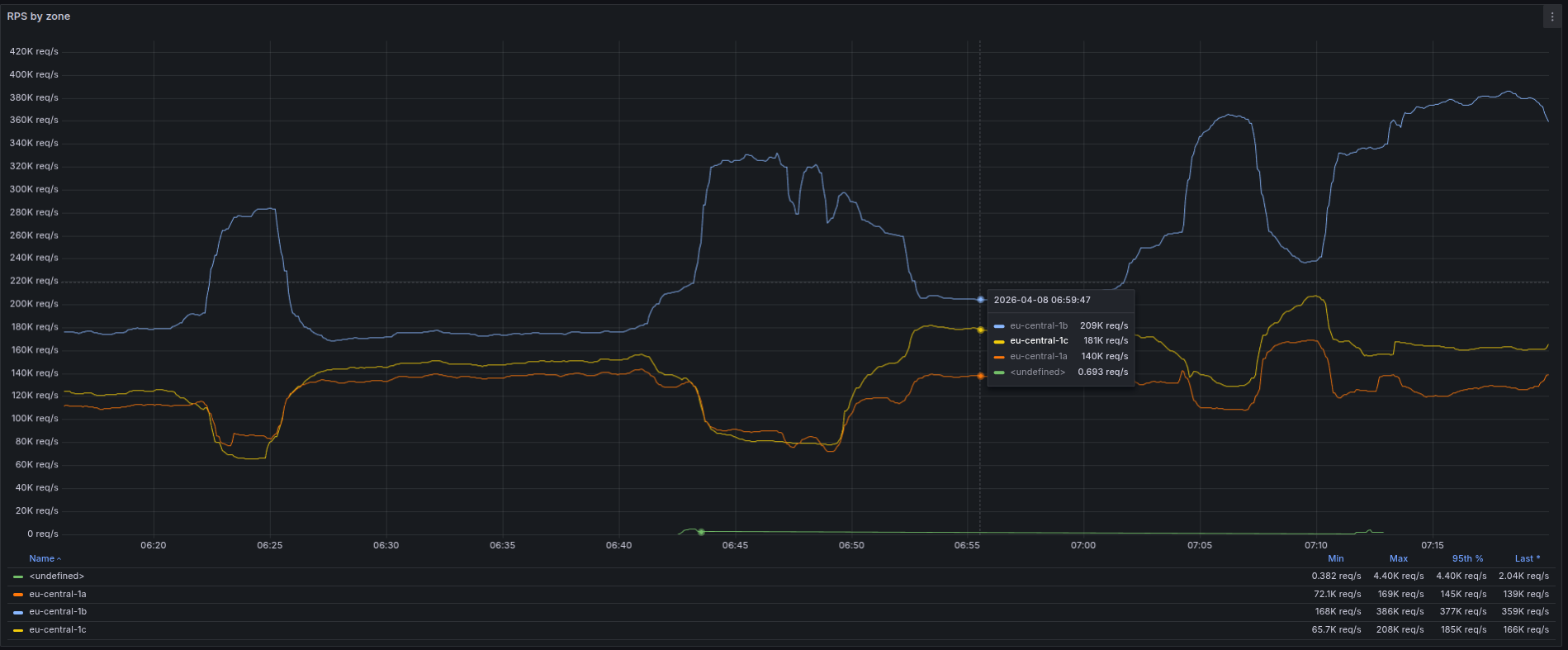
figure 2 - RPS traffic by zone
What we see is flapping of the traffic distribution, which sometimes caused an unexpected latency spike to one of our applications. This flapping was caused by kube-proxy, that thought it might makes sense to flap between zone aware and not zone aware traffic. If you check safeguards, you can read:
4. One or more endpoints does not have a zone hint: When this
happens, the kube-proxy assumes that a transition from or to
Topology Aware Hints is underway. Filtering endpoints for a Service
in this state would be dangerous so the kube-proxy falls back to
using all endpoints.
5. A zone is not represented in hints: If the kube-proxy is unable
to find at least one endpoint with a hint targeting the zone it
is running in, it falls back to using endpoints from all
zones. This is most likely to happen as you add a new zone into
your existing cluster.
Basically what we see in figure 2 is that if zone hints are populated, kube-proxy will write layer 4 rules such that rules are zone aware and we have this large unbalanced traffic split. Later zone hints disappear or are not available for one or more endpoints (4.) and it decides that it is too dangerous and the rules will change to non-zone aware traffic. I don’t know why these hints disappear, but I did not find any when I checked. One of the interesting facts are that we have this flapping all the day for some weeks and it’s most often not an issue, but sometimes a latency spike up to 250ms happened and this is large enough for high traffic low latency applications to fail.
After discussing this in Kubernetes sig-network community channel we
will try to switch to a more persistent service type ClusterIP
configurations by using trafficDistribution: PreferSameZone, that is
now available in Kubernetes. It will provide no flapping for the
traffic distribution. I am looking forward to see the effects.
What about pods?
One other important configuration is that you have a balanced spread
of pods for clients, proxy and backends. This you can influence by setting
topologySpreadConstraints.
The proxy and also application developers already enabled topologySpreadConstraints,
example:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
component: ingress
application: skipper-ingress
This is configuration is important to not create too much of an unbalanced traffic by your clients. Also the targets of the proxy have also to spread evenly so the horizontal pod autoscaling can do its job and keep the load of single pods in bounds.
One last thing
Of course Kubernetes would not be Kubernetes, that everyone loves and hates, if there would not be a missing feature. Beware about the fact that there is no zone aware down scaling.
Kubernetes infrastructure is super interesting, often details matter and sometimes there are missing features, that make you wonder, but all in all I am very happy with it.
If you have any questions or anything to share let me know in Mastodon.